日本のビッグデータ領域を牽引するプロフェッショナル、長谷川氏が登壇!「ビッグデータの歴史とレイクハウス」特別勉強会レポート

アルサーガパートナーズでは、ENGORGIO, Inc. 代表取締役の長谷川氏をお招きし、社内勉強会「ビッグデータの歴史とレイクハウス」を開催しました。(開催日:2025年12月11日)
本勉強会では、Hadoopに代表される初期のビッグデータ基盤からクラウド時代のアーキテクチャ変遷、そしてレイクハウスに至る流れを、技術的背景と組織論の両面から解説いただきました。とくに「技術は流行で置き換わるのではなく、過去の制約と利用者からのニーズ(使いやすさ、コスト・性能・運用負荷・ガバナンス)を解くために必然的に進化してきた」という整理は、日々の技術選定を見直す良い視点になりました。
目次
開催の背景:世界基準の「視座」を手に入れるために
当社では、データ活用支援を進めるうえで、ツールの機能理解に加えて「なぜそのアーキテクチャが主流になったのか?」「先進企業はどんな設計思想でデータを扱っているのか?」を押さえることが重要だと考えています。
また当社は、Databricks社の認定パートナーとして(上位ランク)Select Tierを取得しています(※)。社内でも実装力の強化に継続的に取り組む一方で、技術の“背景”まで含めて理解することで、より再現性の高い提案・設計につなげたいと考え、本勉強会を企画しました。
そこで今回、マッキンゼーやBCG、Databricksといったグローバルファームでの実績を持ち、世界のデータ事情に精通したプロフェッショナル、長谷川さんにお越しいただきました。 第一線で活躍されてきた長谷川さんの視点からデータ基盤の歴史と本質を学ぶことで、私たちの知識を深め、日々の業務における視座を高めること。それが本勉強会の狙いです。
※関連プレスリリース:
アルサーガパートナーズ、データブリックスのパートナープログラムにて「Select Tier」に昇格
長谷川氏について
ENGORGIO, Inc. 代表、マネージングパートナー
東京工業大学大学院を卒業後、大手金融機関、スタートアップ2社、外資系コンサルを経てビッグデータテクノロジー企業へ参画し、同社でのクラウド/オープンソースにフォーカスしたビッグデータコンサルティングサービスを立ち上げ。その後、マッキンゼー日本支社にてQuantumBlackの日本オフィス立ち上げ。ボストンコンサルティング(BCG GAMMA/現BCG X)ではリードデータサイエンティストとしてMLOpsによる組織改革オファリングを推進。と、日本におけるデジタルコンサルティング部隊の黎明期を経験。
その後Databricksの日本におけるプロフェッショナルサービス立ち上げにて、3年で100以上のプロジェクトを提案し、デリバリまで従事。
現在は、有志で立ち上げた企業グループの経営メンバーで、顧客の価値創造に拘った提案とデリバリーに携わるだけでなく、中堅SI企業のデータAIサービス強化の顧問も務める。
その他、データ領域のテクノロジー書籍の翻訳や執筆活動も精力的に行っている。
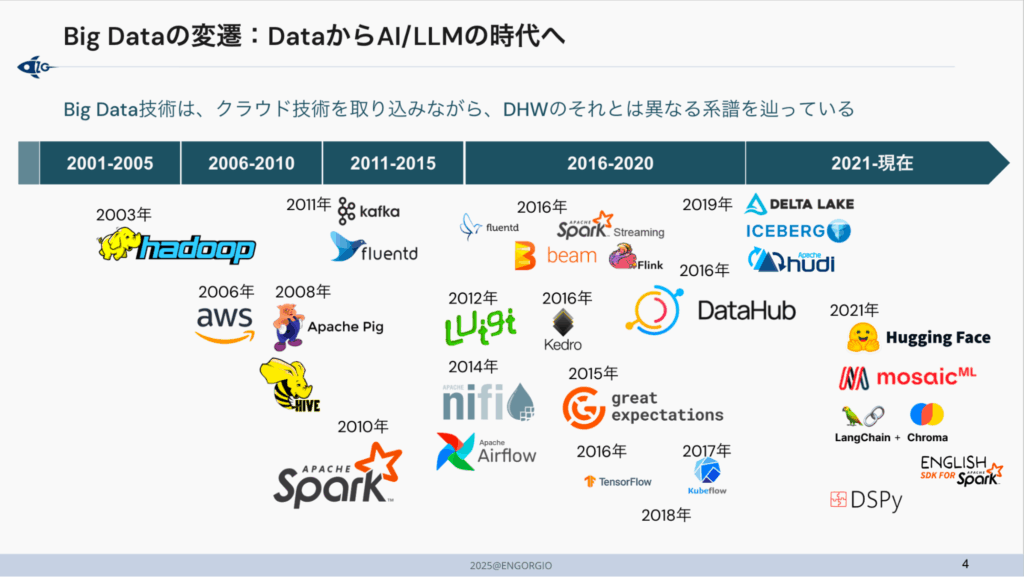
1. ビッグデータの歴史:Hadoopからレイクハウスへ
勉強会の前半は、2000年以前のデータベースの時代から、現在の「レイクハウス」に至るまでの壮大な歴史の振り返りでした。
- 2000年以前:データベース中心
コンピュートとストレージが密結合(サーバ一体型)で、扱えるのは主に構造化データ。設計・運用は専門家依存になりやすいという前提がありました - 2003年~:Hadoopの時代(MapReduce/HDFS)
安価なサーバでの分散処理を可能にし、ファイルベースの大規模データを扱えるように。一方で、オンプレ前提・ネットワーク制約、MapReduceの構造的な遅さ(読み書きがセット)など、次の課題も明確になります - 2006年~:クラウドで”分離”が始まる
クラウドの普及と、ストレージとコンピュートを分ける考え方が現実解になったことで基盤をスケーラブルに扱うことができ、データ量の増加に対応出来るように - 2010年~:Sparkの登場でインメモリ処理へ
メモリ価格の低下とともにインメモリ分散処理(Spark)が登場。中間データを書き込まずメモリで処理し、反復計算や準リアルタイムにも強いアプローチが主流化 - 2011年~:ストリーミング/ノートブック/パイプラインの成熟
Kafka/Fluentd、IPython/Jupyter、Airflowやdbt等のパイプライン管理など、単なる”データ処理”から、再現性・協働・運用を前提にした周辺技術が揃っていきます - 2015年~:品質・メタデータ・MLライフサイクルへ
Great Expectations、DataHub等、TensorFlow/Kbeflow/MLflowなど、データ活用を組織で回すための要素が拡張していきます - 2020年~:Lakehouseの提唱/オープンテーブルフォーマットの進化
DWHとData Lakeの分断を越える流れとしてLakehouseが整理され、Delta Lake(Databricks)、Iceberg(Netflix)、Hudi(Uber)といった“ファイルベースでテーブルを管理する”技術が重要テーマとしてホットに - 2021年~:非構造化データ/LLM時代へ
MosaicML、Hugging Face、LangChain、DSPyなど、非構造化データと生成AIを前提にしたエコシステムが急速に拡大しています
「新しいから採用されてきた」のではなく、「何の制約を外すために技術が進化してきたのか?」という観点で整理できた点が、こうした技術の進化の理解に役立ちました。技術はただ新しくなっているのではなく、「過去の課題(遅い、高い、使いにくい)」を解決するために、進化圧を受けながら、必然的に進化してきたという文脈が非常に腹落ちする内容でした。
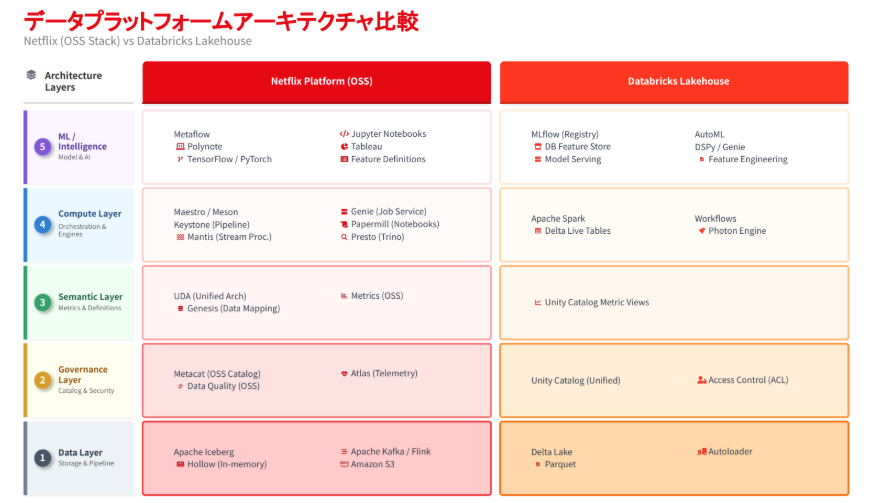
2. Netflixに学ぶ「データ駆動型組織」の真髄
後半は、Netflixの取り組みを題材に、データ駆動型組織が“制度設計”として成立している点が紹介されました。
- 年間で大量の実験(A/Bテスト)を回し、意思決定の中心に実験結果を置く
- エンジニア/アナリスト/データサイエンティストが、共通の作業基盤(例:ノートブック等)で協働できる状態を整える
- データ基盤は「分析のための箱」ではなく、プロダクト改善を回し続けるための装置として設計する
また、同社発の取り組みがオープンソースとして波及し、業界の標準化に影響を与えてきた点も示され、「最先端の課題に向き合うことが、そのまま技術標準を生む」という構造が理解しやすいパートでした。
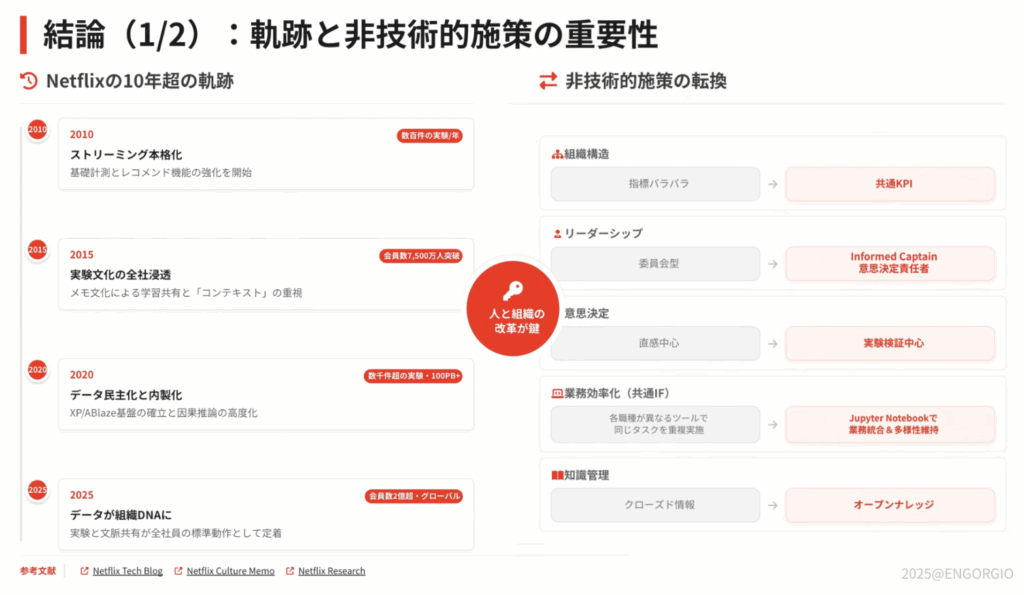
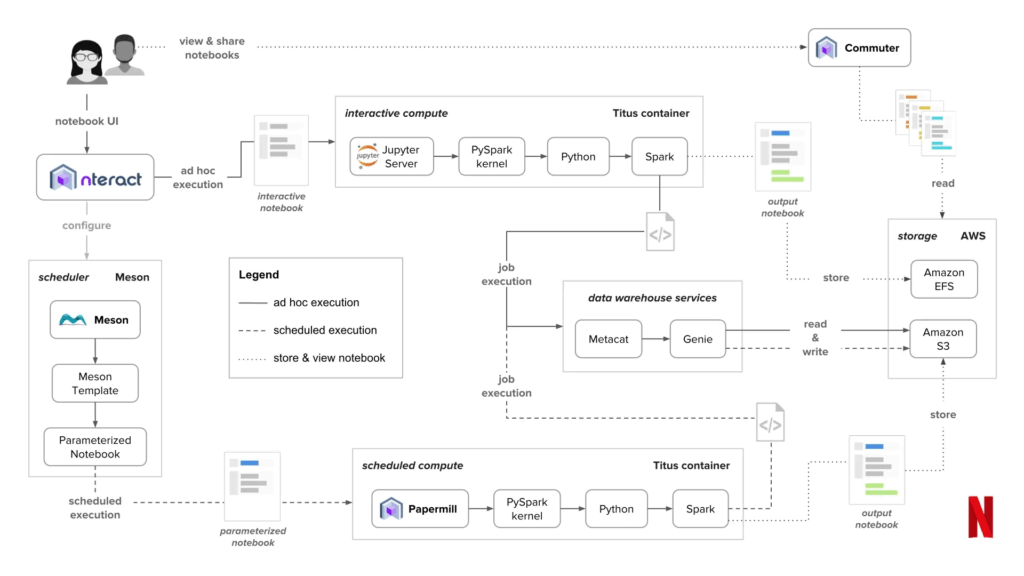
引用: Netflix Tech Blogより
3. DWHとデータレイクの課題を解決する「レイクハウス」
講義終盤では、レイクハウスを「流行語」ではなく、設計思想として捉える重要性が強調されました。
レイクハウスは、データレイクのスケーラビリティと柔軟性に、DWHが得意としてきたガバナンスや性能最適化の考え方を重ね合わせ、データの二重管理やサイロ化を抑えながら、分析からAI活用までを一貫させることを目指すアーキテクチャです。
そのうえで、用語に引っ張られず、次のような“要件”で評価するべきだという視点が整理されました。
- ガバナンス(権限管理/監査/品質)が一元化されているか?
- ストレージとコンピュートが適切に分離され、コストと性能の設計余地があるか?
- 分析・BI・機械学習までが同じデータ基盤上で無理なく接続できるか?
またDatabricksを例に、レイクハウスを実装するための主要コンポーネントがマネージドで提供されることで、構築・運用の立ち上げを短縮しやすい点にも触れられました。
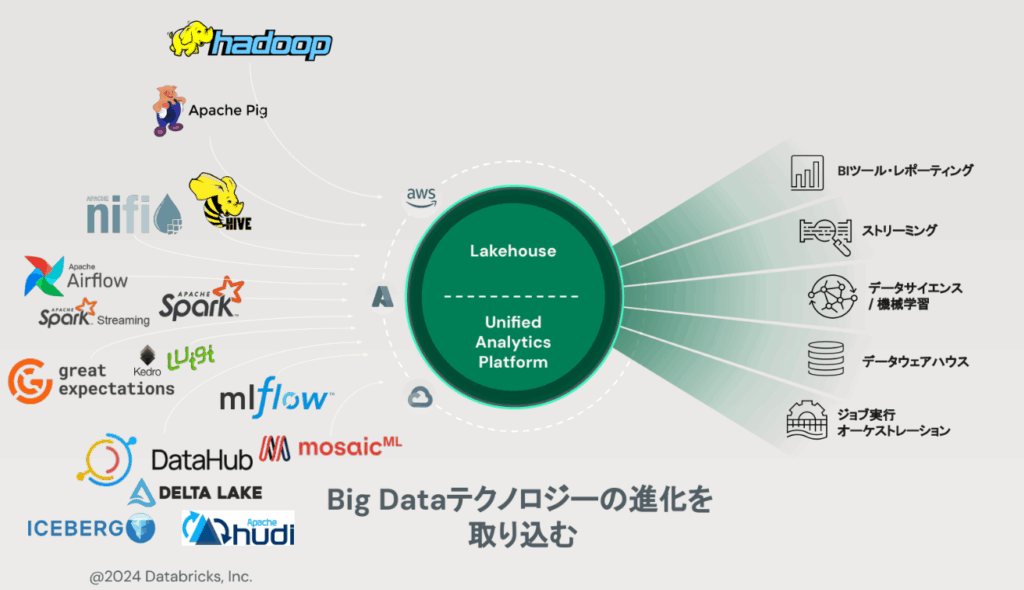
レイクハウスは、これまで分断されていた「データウェアハウス(DWH)」と「データレイク」のメリットを統合し、二重管理やサイロ化といった課題を解消するためのアーキテクチャ(概念)です。
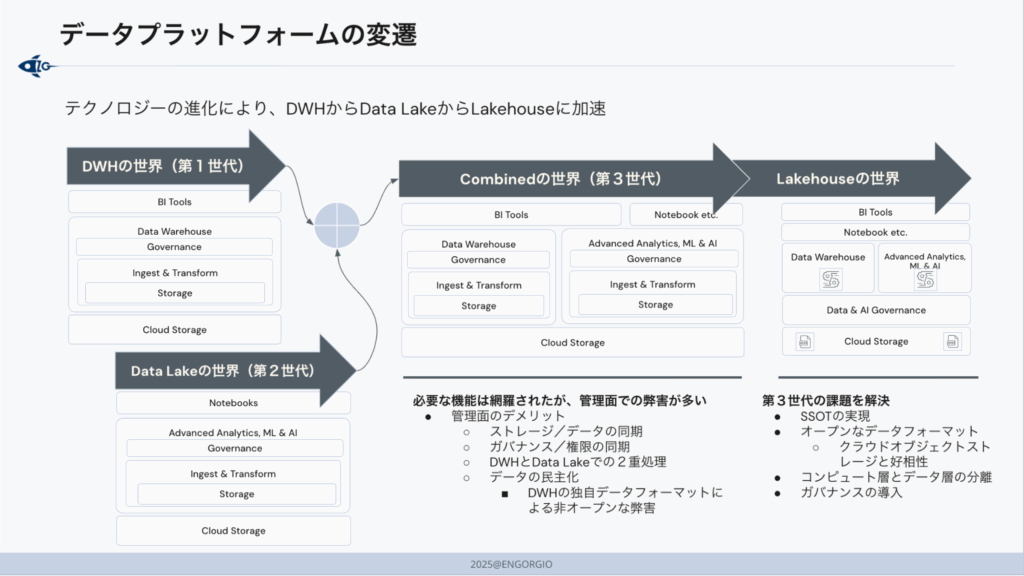
また、長谷川さんは、Databricksがレイクハウス型の設計思想と主要コンポーネントがプラットフォームとして提供されることで、従来は長期間かけて内製で開発とインテグレーションしてきた基盤要素を短期間で揃えやすくなる点を強調していました。
最後に
今回の勉強会を通じて、Hadoopからレイクハウスに至るビッグデータの技術変遷を「課題と解決の歴史」として捉え直すことができました。また、Netflixの事例からは、データ駆動を成立させるために必要なのはツール導入だけではなく、実験を回し続ける仕組みと、それを支える文化・役割設計であることを再確認しました。
当社としても、技術選定をスペックや流行のみで判断するのではなく、組織のフェーズや解決すべき課題(ガバナンス、コスト、拡張性、運用体制など)とセットで設計し、より本質的なデータ活用支援につなげていきます。長谷川さん、長時間にわたるご講義をありがとうございました。

関連ブログ:



