ビッグデータのプロ 長谷川氏・坪井氏が登壇!「データレイクハウスの進化とデータパイプライン設計のベストプラクティス」特別勉強会第2弾レポート

アルサーガパートナーズでは、2026年1月21日にデータ基盤に関する社内勉強会を開催いたしました。
今回のテーマは、「データレイクハウスの進化とデータパイプライン設計のベストプラクティス」。講師として、ENGORGIO, Inc. 代表取締役の長谷川さんと、GeminiData / Mottekoi 代表の坪井さんをお迎えしました。
本勉強会は、2025年12月11日に開催した第1弾データ勉強会「ビッグデータの歴史とレイクハウス」で参加者から大きな反響を呼んだことを受けて実現した、第2弾の取り組みです。
今回は、前半で長谷川さんより「データレイクハウスの生成AIに伴う進化とアーキテクチャの基礎」について、後半では坪井氏さんより「最新のデータパイプライン設計におけるベストプラクティスと実装思想」について、実践的な視点からご講演をしていただきました。
ビッグデータ領域の第一人者でプロフェッショナルである長谷川さんと、卓越した技術力で業界を牽引する敏腕ビッグデータエンジニアの坪井さん。深い洞察と多大な実績を持つお二人による講演は、データレイクハウスの現在地と、これからの設計思想を改めて捉え直す貴重な機会となりました。
目次
本勉強会の目的
当社では、データ活用支援を進めるうえで、ツールの機能理解に加えて「なぜそのアーキテクチャが主流になったのか?」「先進企業はどんな設計思想でデータを扱っているのか?」といった背景を押さえることが重要だと考えています。
前回の勉強会ではビッグデータの歴史とレイクハウスの概念を学び、今回はそこから一歩踏み込み、「なぜレイクハウスが必要なのか」を腹落ちさせると同時に、「どう設計・実装すべきか」を具体的に学ぶことを目的としました。
前回の勉強会の様子はこちらから:
日本のビッグデータ領域を牽引するプロフェッショナル、長谷川氏が登壇!「ビッグデータの歴史とレイクハウス」特別勉強会レポート
また、アルサーガパートナーズは、昨年Databricksのパートナープログラムにて上位に位置する「Select Tier」に昇格しました。こういった背景から、この認定によるポジションをさらに強化すべく、本勉強会のような実践的な機会を通じ、データ活用に関する知見を深めることに注力しています。
関連記事:
アルサーガパートナーズ、データブリックスのパートナープログラムにて「Select Tier」に昇格
登壇者紹介
長谷川氏について
ENGORGIO, Inc. 代表、マネージングパートナー
東京工業大学大学院を卒業後、大手金融機関、スタートアップ2社、外資系コンサルを経てビッグデータテクノロジー企業へ参画し、同社でのクラウド/オープンソースにフォーカスしたビッグデータコンサルティングサービスを立ち上げ。
その後、マッキンゼー日本支社にてQuantumBlackの日本オフィス立ち上げ。
ボストンコンサルティング(BCG GAMMA)ではリードデータサイエンティストとしてMLOpsによる組織改革オファリング推進と、日本におけるデジタルコンサルティング部隊の黎明期を経験。
その後、Databricksの日本におけるプロフェッショナルサービス立ち上げにて、3年で100以上のプロジェクトを提案し、デリバリまで従事。
現在は、有志で立ち上げたグループの経営メンバーで、顧客の価値創造に拘った提案とデリバリーに携わるだけでなく、中堅SI企業のデータAIサービス強化の顧問も務める。
その他、データ領域のテクノロジー書籍の翻訳や執筆活動も精力的に行っている。
坪井氏について
Mottekoi 代表
富士通、Akamai、SplunkといったグローバルIT企業でのエンジニア経験を経て、2020年夏にDatabricksへ参画。同社におけるプロフェッショナルサービス部門の採用第1号として、Resident Solution Architect(エンジニア)の立場で、長谷川氏らとともに数多くのプロジェクトデリバリーに従事。
その後、Specialist Solution Architectとして、特に高度なアーキテクチャ、データパイプライン最適化やセキュリティに関する実務的なアドバイスを、様々な顧客に対して主導。
専門領域は多岐にわたり、アーキテクチャ設計、データパイプラインの最適化、およびセキュリティに深い知見を持つ。
現在はMottekoiの代表を務め、長谷川氏ら元同僚らと生成AI関連やデータ関連のプロジェクトに携わりながら、培った専門性を活かして幅広く活動している。
【前半】長谷川氏:データレイクハウスの生成AIに伴う進化とアーキテクチャの基礎
1. 生成AI時代に進化する「レイクハウス」のレイヤ構造的解釈
まず、長谷川さんより、レイクハウスのレイヤ構造的解釈についての解説が行われました。
レイヤとは、データ基盤の中で役割の違う仕事を混ぜないための整理するための設計上の区分を指します。
当初のレイクハウスは、「GUIツール」「処理エンジン」「データ+AIガバナンス」「ストレージ」の4つの重要なレイヤで構成されていました。この4層のレイヤでは、データレイクやDWH(データウェアハウス)間で必要だったデータ移動やコピー、二重管理の必要がなくなった点が大きなポイントでした。
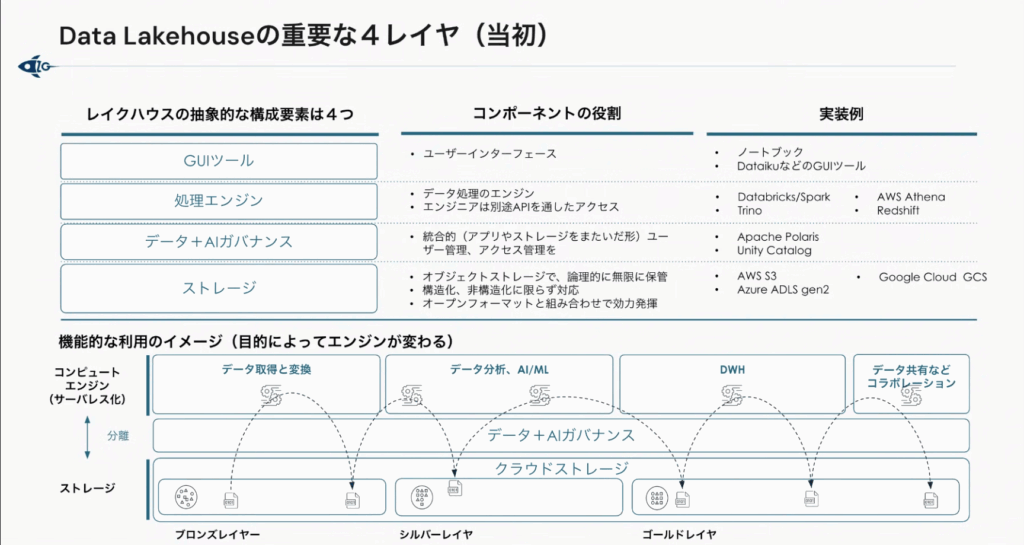
長谷川さんは、従来のDWH等のデータ基盤の標準的な4層構造では、生成AIが進化する中で使いこなすには限界があると指摘。これまでの4層は、人間が構造化されたデータを集計・分析することを前提としていたからです。
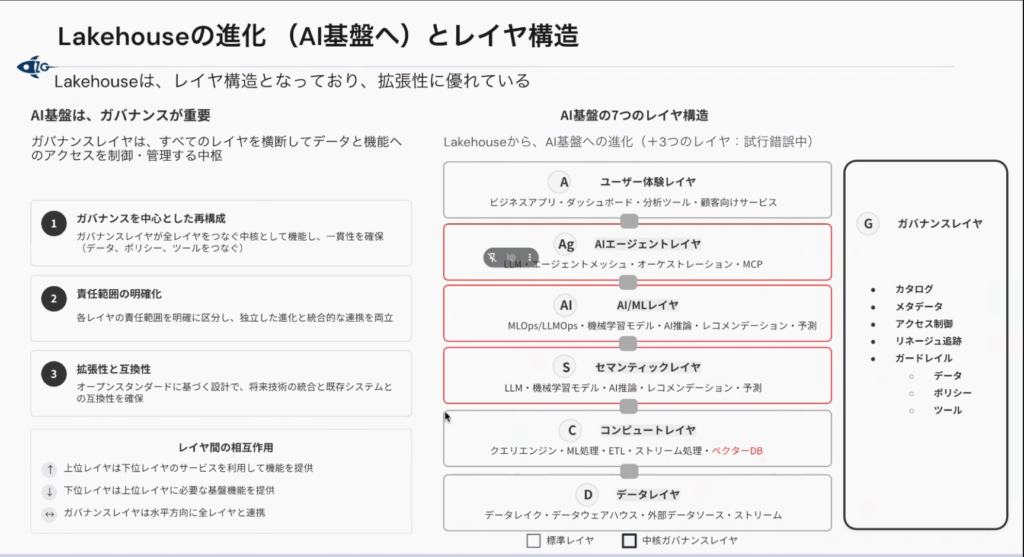
昨今の生成AIの進化に伴い、レイクハウスも進化し、より生成AIに対応するようになり、新たな3層を含む7層構造へ進化しているように見えます。
- AIエージェントレイヤ:自律的なAI処理を制御するフレームワーク
- セマンティックレイヤ:データの「意味情報(どの項目を組み合わせれば売上になるか等)」を管理し、AIが正しくデータを解釈できるようにする
- AI/MLレイヤ:機械学習モデルや大規模言語モデルのライフサイクルを管理する
これにより、レイクハウス内で一体化していた役割や責務がより可視化。従来の4層構造から7層構造への進化は、レイクハウスが単なるデータ基盤から包括的なAI活用基盤へと変貌を遂げ、生成AI時代におけるデータ活用の新しいスタンダードとなったことが理解できました。
2. 「ETL」から「ELT」へのマインドセットの転換
続いて議論は、データをどのように処理・管理すべきかというアーキテクチャの話へと展開。
従来主流だった「ETL(Extract-Transform-Load、抽出・変換・書き出し)」では、ソースデータをデータベース/DWHに入れる前に加工(Transform)する必要がありました。これには事前の要件定義やシステム開発が伴うため、実際にデータが使えるようになるまで数ヶ月〜1年以上かかることも珍しくなかったとのこと。
しかしこれでは、あとから別のデータ項目が必要になったときに、元の場所から取り込み直す必要(追加の要件定義とシステム開発)があり、変化の激しいAI時代には対応できません。これに対し、レイクハウスでは「ELT(Extract-Load-Transform、抽出・書き出し・変換)」が推奨されます。まず、ソースデータをそのままレイクハウスの基盤に保存(Load)してしまい、その後、ユースケースに応じて加工(Transform)するアプローチです。これにより、システム開発を待たずに、アジャイルに処理し、データ活用を始めることが可能になります。
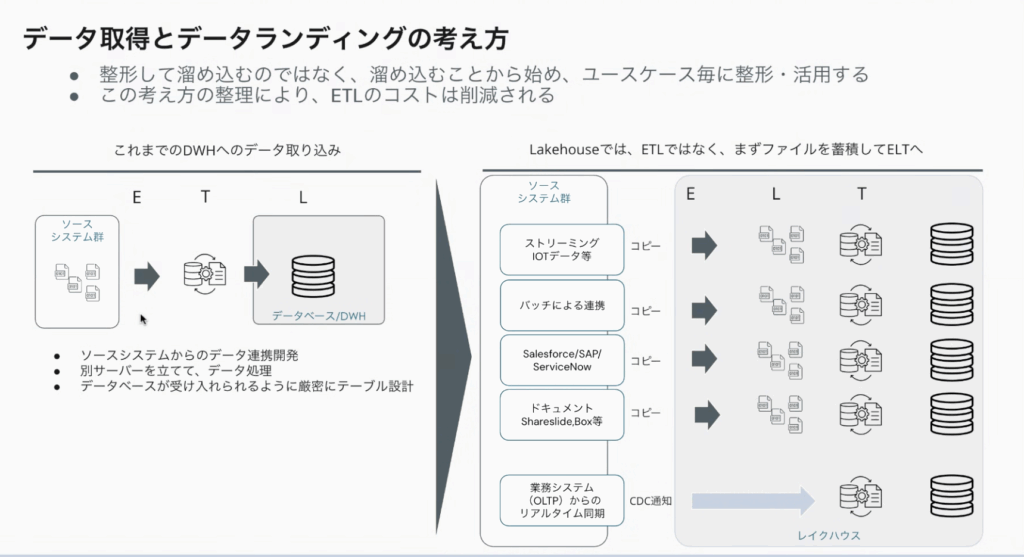
この「とりあえず全部入れて、中で賢く加工する」というELTの思想を、具体的にどう管理するかが、次のメダリオンアーキテクチャという仕組みにつながります。
3. データの品質を育てる「メダリオンアーキテクチャ」の鉄則
続いて、データパイプラインに関する基礎的な内容に移ります。データパイプラインとは、レイクハウスに閉じる処理である「データと一連の処理の流れ」を指しています。
前述のELTの思想で「とりあえず入れた生データ」を、どうやってビジネスで使える「価値あるデータ」に磨き上げるのか。そのための設計指針が、品質を上げていくために、データを3段階に分けて管理する「メダリオンアーキテクチャ」です。
<概念としてのメダリオンアーキテクチャとは?>
- Bronze(ブロンズ):ソースから持ってきたままの生のデータ。加工を一切しないため、万が一のときの証拠として残せる
- Silver(シルバー):複数のデータを統合し、無駄なものを除去(クリーニング)した整ったデータ
- Gold(ゴールド):特定のビジネス要件に合わせて集計・整形された、ダッシュボードやAIがそのまま使える完成データ
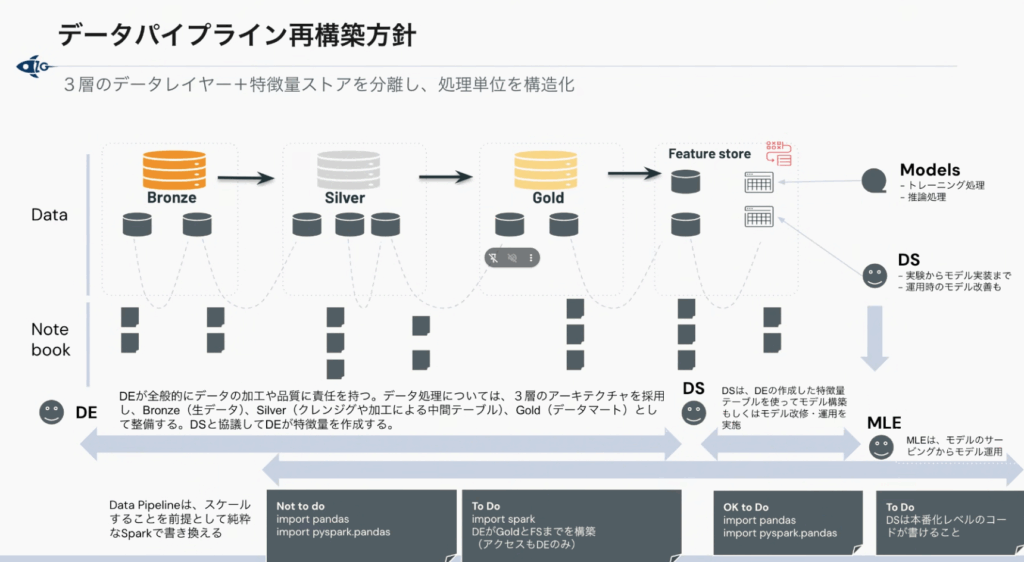
長谷川さんがこのパートで強調したのは、これらBronzeからGoldへの各段階で、「必ず物理的なテーブルとしてストレージにピン留めする(保存する)」という点です。
開発効率を求めてメモリ上だけで処理を流すと、パイプラインが途中で詰まるなどの障害が起きた際に、「どこでデータが壊れたか」が見えなくなり、復旧に多大なメンテナンスコストがかかります。
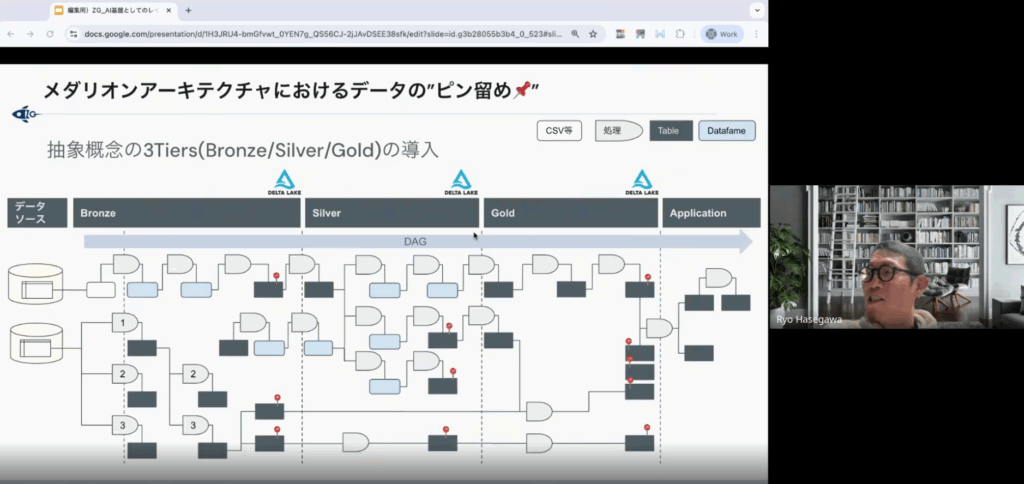
適切にピン留めすることで、パイプラインのGoldでエラーが起きたとき、Bronzeに遡って全てを流し直す必要はありません。物理保存された中間地点であるSilverから再スタートすれば、数分で復旧できます。
※メダリオンはあくまで概念なので、3層である必要はなく、パイプラインの特性や運用チームによっては5層や7層の場合もある
現場で良く起こる「障害が起きたときに、どこまで戻って修正すればいいか分からない」という問題。この“ピン留め”こそが、数千のテーブルを管理するプロの現場を救う唯一の手段であると解説し、とても実務的なアドバイスとなるパートでした。
【後半】坪井氏:最新のデータパイプライン設計におけるベストプラクティスと実装思想
4. ビジネス加速する「宣言型」パイプライン(SDP)の推奨
後半パートからは、坪井さんにバトンタッチし、より実践的な「データパイプライン設計」の解説が行われました。
坪井さんは、パイプライン実装の進化を「手続き型処理」から「宣言型処理」への転換であると説きました。ここで登場するのが、Databricksが提供するパイプライン専用ツール「Lakeflow SDP」です。
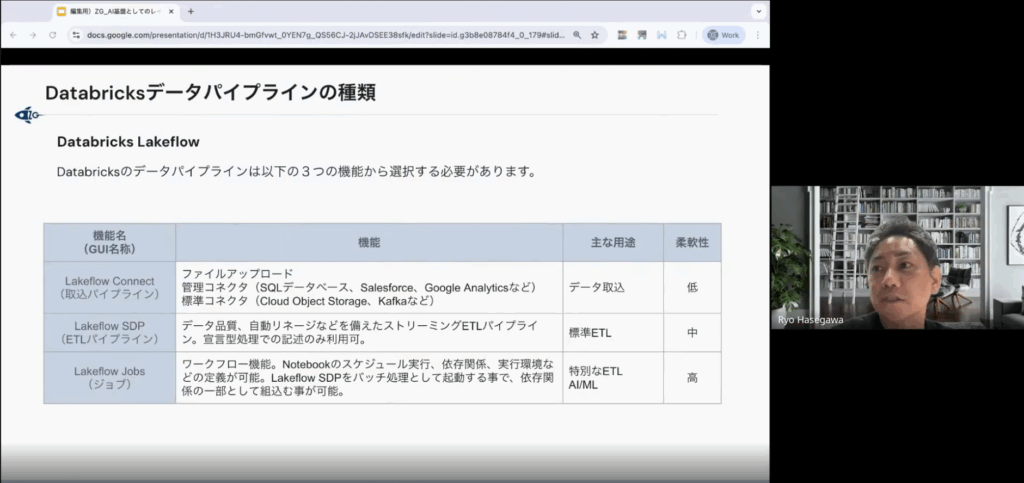
まず、データを取り込み、加工するための種類は以下の3つですが、坪井さんは「まずはSDPでできないかを検討すべき」と強調しました。
- Lakeflow Connect:UIポチポチで設定。設定は楽だが、複雑な加工は苦手
- Lakeflow SDP (Spark Declative Pipeline):「宣言型」で書く専用ツール
- Lakeflow Jobs:従来のNotebook(Python/SQL)でゴリゴリ書く「手続き型」の手法
<「手続き型」と「宣言型」の違い>
初心者の方が最もつまずきやすいこの2つの違いは、以下の通りです。
- 手続き型(Notebook):ユースケースごとの完全最適化が可能。一方で、「どうやってデータを動かすか」にエンジニアの工数の大半が奪われており、書いた本人にしか直せないといった属人化や膨大なメンテナンス時間が発生する
- 宣言型(SDP):「このデータから、こういう結果を作りたい」という目的を記述するだけで、あとはプラットフォームが最適な手段を選択するのみ。8割〜9割のコストパフォーマンスで各ユースケースに対応し、チームの誰もがメンテナンス可能
<なぜ「Lakeflow SDP(宣言型)」が推奨されるのか>
坪井さんは、手続き型がビジネスを停滞させるリスクを指摘し、宣言型を推奨する理由を以下の通り述べました。
- リネージ(データの家系図)の自動可視化:ソースからテーブルまでの依存関係をUI上で自動可視化。コードを読み解かずともデータの流れが一目で把握でき、属人化を排除する
- データ品質と監視:「このカラムにNULLが入ったら処理を止める」といった品質ルールを数行書くだけでシステムが常時監視。サイレントなデータ障害を未然に防ぐことができる
- 自動最適化:クラスターサイジングやデルタテーブルのメンテナンス、データ品質の監視をシステムが自動で実行することができる
- ストリーミング処理とバッチ処理の切替:前回どこまでデータを読んだかという差分管理(チェックポイント/CDC)を自動制御するため、手書きでの複雑な記述が不要になり、余計な作業が削減される
- 開発品質:手書き型における自作のコードでは、APIのバージョン依存やSparkのチューニング不足により、知らぬ間にパフォーマンスが低下傾向に。SDPは基盤側で実行エンジンを常に最新に最適化するため、誰が書いても高い品質と安定性を維持する
- 自動CDC:これまで手動で1つずつ書く必要があったCDCをシステムが自動で制御。「どこまで読んだか」を管理する複雑なロジックを自作する必要はなくなり、開発工数を削減
- オープンソース化:「独自の便利機能(SDP)」はベンダーロックインを懸念されやすかったが、基盤技術である「DLT」はSpark 4.0でオープンソース化

坪井さんは、過去5年で、宣言型で書けないような特殊なプロジェクトは3件ほどしかなかったと話します。難しいコーディング(手続き型)に時間を費やすのではなく、SDPのような宣言型の仕組みに任せられるところは任せるべきだと伝えました。
99%のケースでは、人間が苦労して手書き型で完全最適化を目指すよりも、宣言型に任せて楽に90点を出し続ける方が、運用も管理も圧倒的に楽でコストパフォーマンスが良いとのこと。それが、Lakeflow SDPが推奨される最大の理由です。これこそが、開発効率と安定性を両立させる唯一のベストプラクティスであり、「エンジニアの働き方そのもの」をアップデートするものであると結論付けました。
5. ストリーミング処理を前提とした設計思想
前パートで解説されたLakeflow SDPは、基本的にストリーミング処理が前提で実行されていると坪井さんは述べました。これは、単にリアルタイム性を求めるものではなく、運用の自動化と低コスト化を両立させるための戦略的な選択です。
従来のバッチ処理では、「前回どこまでデータを読んだか」という差分管理を人間が記述する必要がありましたが、ストリーミング処理であれば、システムがチェックポイントという機能で読み込んだ箇所までを自動管理してくれます。
バッチ処理での実装も可能ではあるものの、特にメリットはないため、ストリーミング処理として記述したLakeflow SDPをバッチで動かすことを推奨しています。
この機能を実装するために、以下の2つのテーブル設計で構成されています。
- ストリーミングテーブル:データソースから来るデータをひたすら追記し続けるパイプ役となる動的なテーブル
- マテリアライズドビュー:ストリーミングテーブルをソースに、データの変更分だけを再計算する増分更新機能を持つため、通常のビューより劇的に高速
坪井さんは、システムが差分管理を自動制御することで開発工数を削減し、「ストリーミングテーブル」と高速な「マテリアライズドビュー」の組み合わせによって、効率的なデータ活用を実現することを強調しました。
最後に
今回の勉強会では、レイクハウスがAI活用の基盤へと進化し、その実装においては宣言型のデータパイプライン(Lakeflow SDP)やストリーミング処理の活用が不可欠であると解説していただきました。
各パートごとのQ&Aタイムでは、多くのエンジニアやコンサルタントから質問が寄せられ、第1弾以上に反響の大きい勉強会でした。
複雑な処理の管理は進化したプラットフォームに任せ、エンジニアやコンサルタントは「どのようなデータを作ればビジネスが成長するか」という本質的な設計に集中すべきであるというメッセージ。これは、これからのデータ開発における重要な指針となるでしょう。
アルサーガパートナーズでは、こういった実践的な勉強会を継続的に実施しています。今後も勉強会を通じて、メンバー一人ひとりが技術力を磨き上げ、日頃お客様の支援をさせていただく中で、より本質的なお悩みに沿ったソリューションを提供してまいります。
長谷川さん、坪井さん、貴重なご講義をありがとうございました。
(文=広報室 白石)
関連ブログ:
日本のビッグデータ領域を牽引するプロフェッショナル、長谷川氏が登壇!「ビッグデータの歴史とレイクハウス」特別勉強会レポート
【Databricks DATA+AI SUMMIT 2025 参加レポート!】イベント概要と現地で感じた熱気をお届け
【Databricks Data + AI Summit 2025 】マーケティングフォーラムレポート



